Worldreader Query Data Project
A Capstone Project for the Data Science and Big Data course at Universitat de Barcelona.
Query Data Project
Created by Cary Lewis, Aina Pascual, Patricia Araguz and Enrique Rodríguez
UB Data Science and Big Data Capstone Project
Thank you to Worldreader for granting us access to its data and for supporting our Capstone Project.
- Project Background
- Project Scope and Methodology
- Project Work
- Findings and Results
- Conclusions
- Possible Next Steps
- References
Project Background
Worldreader is a non-profit organization working to reduce illiteracy through its reading applications and sponsorship programs. The organization has a collection of over 40,000 books in more than 40 languages with the mission “to unlock the potential of millions of people through the use of digital books in places where access to reading material is very limited.”
The project team approached Worldreader as their large collection generates significant amounts data and particularly through the Worldreader Open Library for mobile phones application.
Worldreader was interested in the proposal of examining their data and in particular the organization wanted to focus on the queries from their mobile application. The project’s aim was to examine the search query data with Worldreader providing a dataset of search queries and the corresponding fields from their application. All data provided would be anonymized and not include personal data in any form.
Project Scope and Methodology
The Project Scope was to analyse queries made by users on the feature phone application by using clustering techniques to identify similar searches. The result of the project would be to give Worldreader a better grasp on what their users are interested in reading and algorithms that the organization could use to improve upon its search queries and results in the future.
The majority of the queries consisted of short text searches, few words, requiring us to supplement the data. In order to use topic modeling techniques such as Latent Dirichlet Allocation (LDA) and Non-negative Matrix Factorization (NMF), we ran the queries through the Google Books API to pull book descriptions.
The models used LDA and NMF are unsupervised techniques for topic discovery in large document collections. These algorithms discover different topics represented in a set of documents and how much of each topic is present in a document (or corpus).
Each algorithm has a different mathematical underpinning:
- LDA is is based on a bayesian probabilistic graphical modeling
- NMF relies on linear algebra.
Both algorithms take as input a bag of words matrix (i.e., each document represented as a row, with each columns containing the count of words in the corpus) and produce 2 smaller matrices:
- a document to topic matrix (no documents * k topics)
- a word to topic matrix (k topics * no words) that when multiplied together reproduce the bag of words matrix with the lowest error.
The output of the derived topics generated by both models involved assigning a numeric label to the topic and printing out the top words in a topic.
NMF and LDA are not able to automatically determine the number of topics and this must be specified.
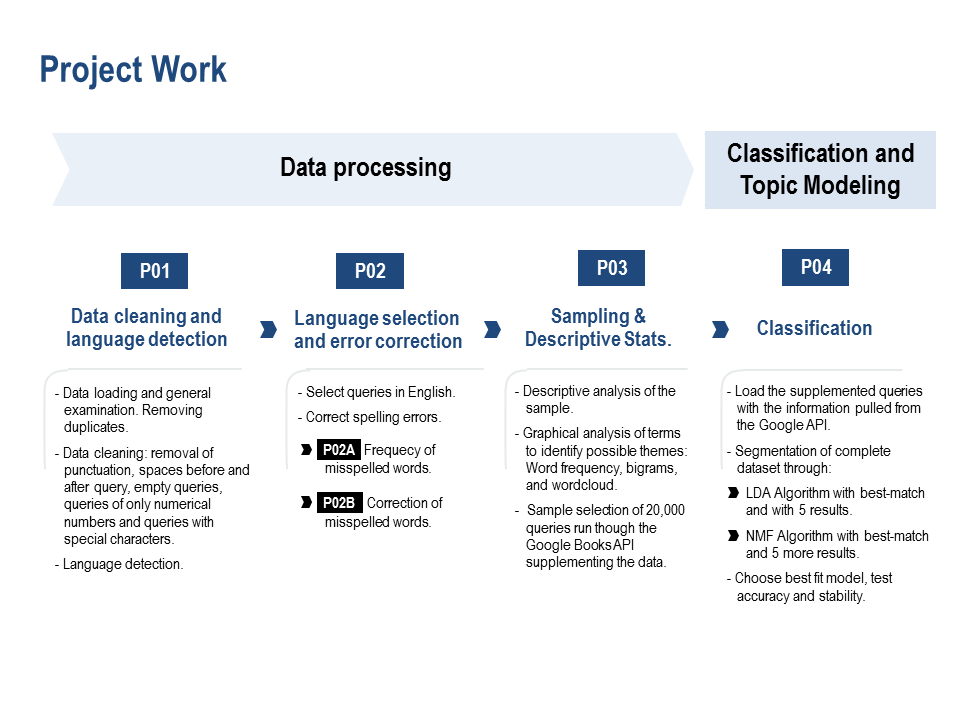
Project Work
For an indepth review of the project work and code see the Capstone’s Jupyter notebook.
Flow Chart of Data in Capstone Project
Worldreader provided our team with 6 CSV files consisting of over 3,000,000 queries and related information.
| customer, | country, | url, | query, | created_at |
| 157260, | "KE", | "/Search/Results?Query=New+Testament&Language=", | "New Testament", | "2016-12-27 15:48:16.893" |
| 157261, | "PH", | "/Search/Results?Query=circles", | "circles", | "2016-11-12 18:14:11.933" |
| 157261, | "PH", | "/Search/Results?Query=japanese", | "japanese", | "2016-11-18 17:15:54.19" |
Reviewing the fields associated with the queries with Worldreader we were told the customer ID was not stable, as sessions would break and did not permit a clear idea of individual user queries.
It was discussed with Worldreader if it would be beneficial to focus on certain countries and it was determined to not be necessary.
Data Cleaning and Language Detection
After loading the data:
- We removed the duplicate queries of each user
- This permitted us to see the individual unique queries from the users - for the puprose of this work duplicate queries (of individual users) could add bias in our topic modeling work with certain queries possibly being overly represented.
- We then also removed punctuation, stop words, irregular spacing at the beginning or end of queries, empty queries or queries that only contained numerical numbers and special characters
- Removing these pieces ensured our scripts would run properly without failing
- We used textblob and langdetect to determine query languages
Language Selection and Error Correction
We decided to use English queries as it would permit us to use the models more effectively. All other queries of the other languages were removed from our data set.
After selecting the English queries we had validated queries and corrected misspellings within words.
Sampling and Descriptive Stats
We needed to select a random sample of 20,000 queries to run as we were not able to run the all queries due to time and API limitations. Using the sample set of 20,000 queries gave us a statistical significance of 99% and was representative of all our query data. Using the random sample of the corrected words we could use this for comparison against the total query data.
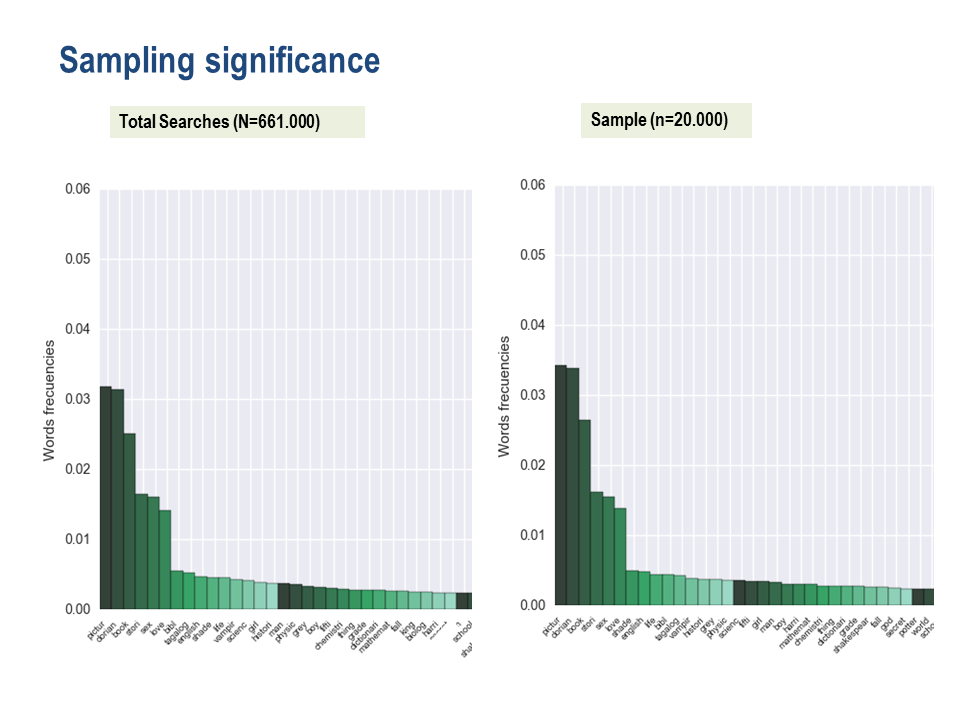
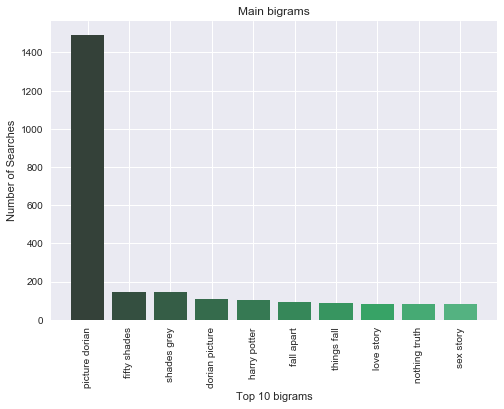
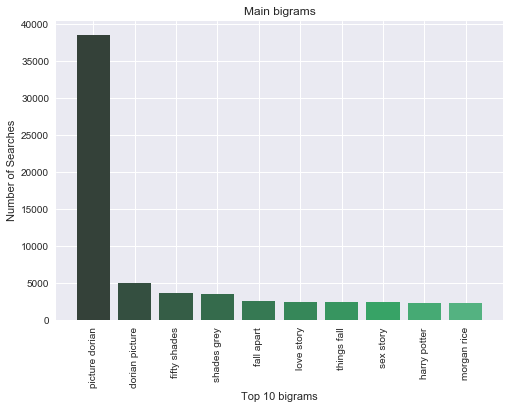
Generated a word cloud with the most used terms and identified the 10 first bigrams depending on their frequency of occurrence.

| 10 Most Frequent Bigrams from Sample Data | 10 Most Frequent Bigrams from Total Query Data |
 |
 |
Classification and Topic Modeling
Supplementing the sample of 20,000 queries with the Google Books API
- Retrieved from the books: title, author, category and description with the Google Books API for each query
- We were limited to a 1,000 daily searches of Google API (daily query limit per user).
- Processed the information obtained to identify which book matches best (from a total of up to 5 candidates) depending on the appearance of terms in their title, author, and description.
- We returned a total of up to 5 books (the first being the best match) provided that the percentage of the words be greater than 60% in the query that appear in the title of the book. If the search words have a percentage of appearance higher than 50% in the returned author, we consider that it is a search by author and we labeled it as such. We would later remove the author queries from our data set as we only wanted to work with queries for titles.
Defining Number of Topics
Since both LDA and NMF need “k” number of topics to run we used the perplexity measure and an iterative approach to define the most suitable number of topics for our data.
Low perplexity indicates that the probability distribution of the model is good at predicting the sample.
| K | Perplexity |
| K=5 | 249.75001877 |
| K=10 | 254.351936899 |
| K=15 | 250.76157719 |
| K=20 | 251.955603856 |
| K=25 | 254.939880397 |
After seeing the results we determined that 15 was the best number of topics.
We prepared the files to generate LDA and NMF models on the descriptions obtained from the sample with the Google Books API
- We prepared work files to generate the LDA and NMF models:
- We used 80% of the sample to construct the models (train)
- We used 20% of the sample to validate the models (test)
- We ran LDA train with the 5 suggestions (complete train) and again with the best match train.
- We ran NMF train with the 5 suggestions (complete train) and again with the best match train.
Comparing the results of the two models with the complete train versus the best match train we saw that the complete train models identified topics more accurately.
- We tested the complete train models of LDA and NMF against one another with the remaining 20% of the sample:
- We then generated a csv file with the predictions from both of the models
Findings and Results
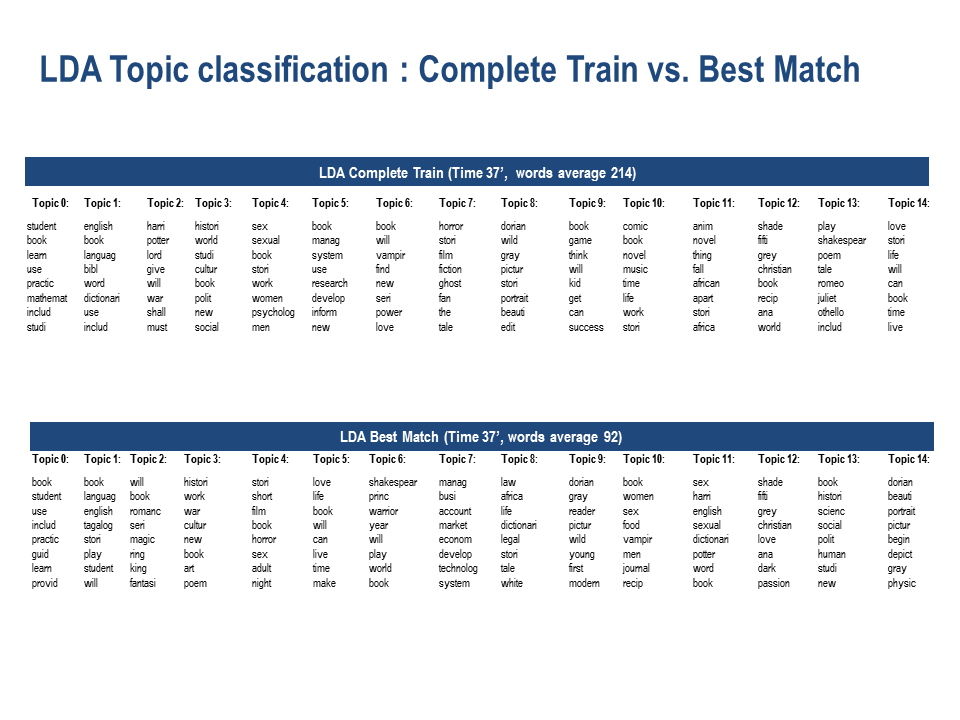
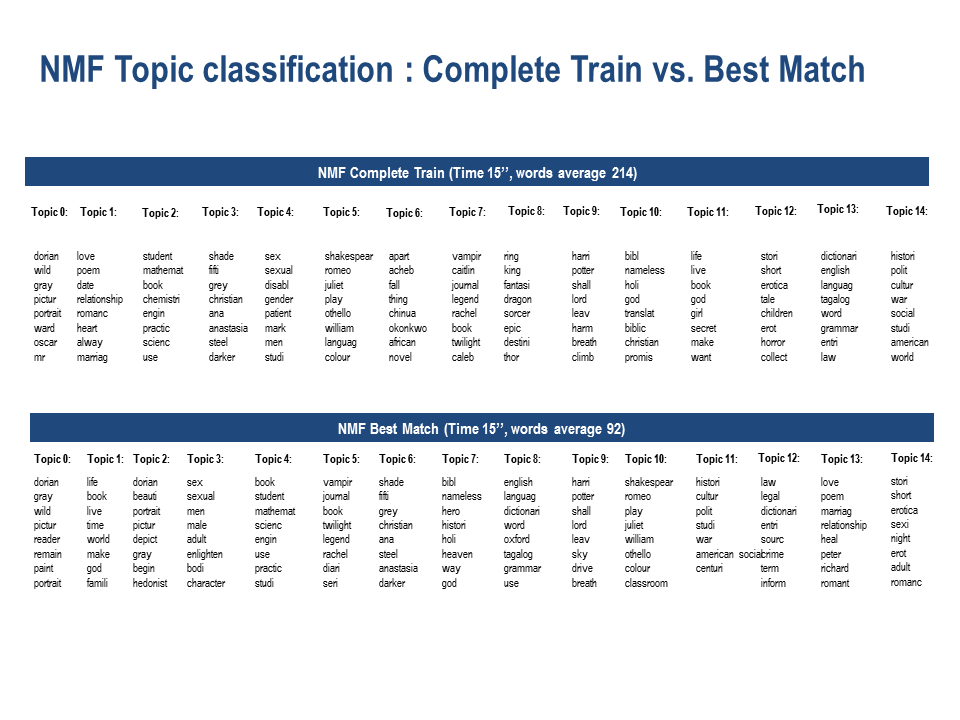
The complete train for both the LDA and the NMF topics were more accurate than the best match as topics were more distinguishable from one another. In the best match for both models some words would appear in more than one topic.
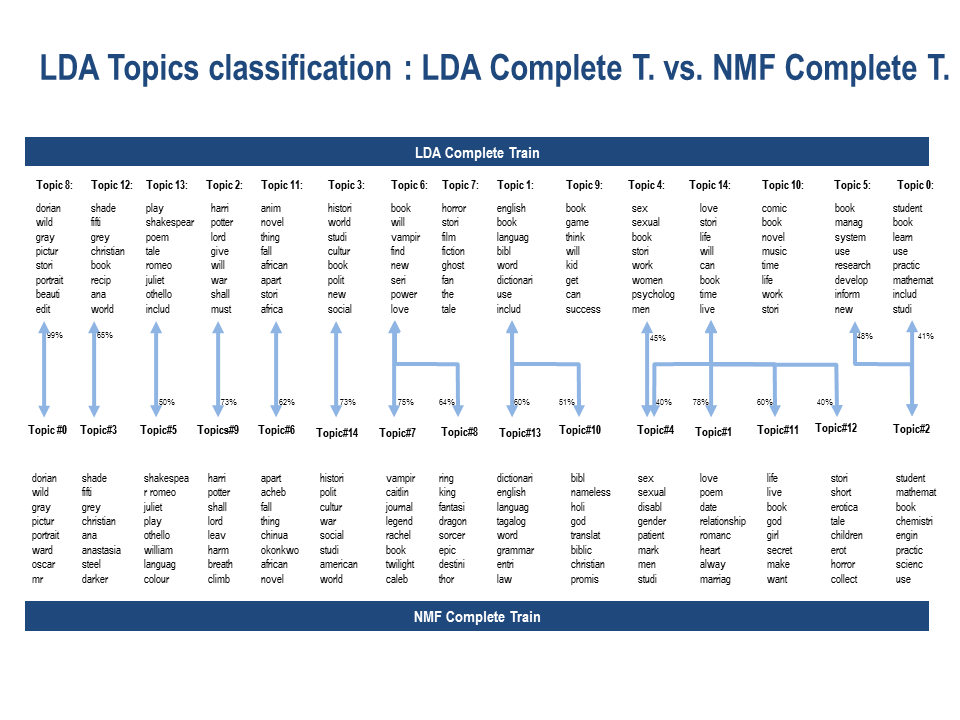
We compared the complete train of the LDA and the NMF classifications against the test results. The following figure shows the overlap between the two classifications. Based these results we determined the NMF complete train to be a more accurate model at this time for our data.
We then grouped the NMF complete train topics into similar categories and assigned to each group a google category. The Google categories did not reflect the NMF complete train grouping when looking at the number of searches by title and categories in the sample.

Conclusions
- LDA and NMF use information about the word co-occurrences to extract the latent topics of the data. For this reason, they promote the predictive capacity of the titles of the books in the categories.
- Topics generated by LDA are close to human understanding, in terms of grouping co-occuring words together. However, these topics may not necessarily be the ones that distinguish different groups of documents-sometimes enforcing the documents to be sparse and specific in topics may help.
- The results of LDA seem unstable and are different depending on the sample of 80% chosen.
- When perplexity was calculated LDA seemed to be more stable for 5 or 15 topics. 15 topics seemed to reflect more precisely the diverse range of documents.
- NMF can be mostly seen as a LDA of which the parameters have been fixed to enforce a sparse solution. It may not be as flexible as LDA if you want to find multiple topics in single documents (e.g., from long articles), but it usually works better with short texts of different nature.
- NMF is faster than LDA for short text analysis, its computation time is lower.
- For our data, NMF seems to be a more stable model both with the best match and with all the suggestions.
- For the purposes of this work, we think the results of NMF complete train help us to understand better user’s type of searches and recurrent topics.
Possible Next Steps
Classification of queries based off user information (if provided)
- Classification of queries based off user information
- Supplement data further with user profile information.
- Supplement data further with information related to success or failure of the search results.
- Increase sample size to see if it improves the function of the models. Test different sample sets.
- Analysis of organization's catalog, if provided.
- Try to find other libraries with description. We could not access to any as good as Google Books API.
- Compare the supplemented queries with the information extracted from the Google Books API against the organizational book catalog:
- Identify the catalog books in high demand
- A list of books in high demand and not part of the catalog
- Create a recommenders system of the catalog based off the queries
- Query Classification Methodologies:
- Test LDA removing words of low frequency.
- Use PCA to try to find core topics within the data. Feature extraction method before NMF and LDA
- Apply TextRank with the descriptions to extract keywords and run the models.
- Apply technical analysis for graphs of the hyperonyms of the main search terms, using the NLTK library to retrieve WordNet hyperonyms.
References
- https://www.quora.com/What-are-the-pros-and-cons-of-LDA-and-NMF-in-topic-modeling
- https://medium.com/@aneesha/topic-modeling-with-scikit-learn-e80d33668730
- http://www.kdnuggets.com/2016/07/text-mining-101-topic-modeling.html
- https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4597325/
- http://aclweb.org/anthology/D/D12/D12-1087.pdf